How We Oops-Proofed Infrastructure Deletion on Railway
If you’ve ever accidentally applied a Terraform or Kubernetes config that nuked production, you probably don’t even want to remember what it felt like. That split second when your terminal hangs, Slack blows up, automated alerts are triggered, and you realize you have just pulled the plug on your entire system is the kind of mistake that makes you double check every command for weeks afterward.

The truth is, this isn’t a skill issue. It's the tools you use to interface with infrastructure that are to blame.
On Railway, rather than nuking all your resources right away, you get a 48-hour grace period where you can undo deletions. We shipped this behavior for project deletions and now they’re available for persistent volumes. Here’s what it looks like in action:
You might just shrug and think, “nice.” But what looks like a simple feature on the surface actually hides a lot of complexity under the hood, especially when it involves actions connected to real machines in a datacenter you operate.
How it works under the hood
Temporal and durable execution
We use Temporal as our workflow engine, which allows us to build reliable and stateful background processes. It maintains a complete event history for each workflow, and makes it possible for business logic to be replayed, recovered, or paused at any point in time.
If you’re new to Temporal, there are a few foundational concepts worth knowing: Workflows, Activities, and Signals.
A Temporal Workflow defines the orchestration logic of your application. It is composed of Activities, which are independent functions that typically perform side-effecting operations such as API calls, database writes, or long-running tasks. Because these Activities are prone to failure, Temporal provides built-in reliability features, such as automatic retries and the ability to run Activities for arbitrary durations without concern for process crashes or restarts.
In addition to Workflows and Activities, Signals provide a way to send external input to a running Workflow. This makes it possible to adjust behavior or provide new data at runtime without restarting the Workflow. Signals are especially useful for scenarios like updating job parameters, canceling a task, or notifying the Workflow of an external event.
Finally, Temporal ships with a built-in web UI that allows you to inspect details of past and present Workflow Executions, which is useful for debugging.
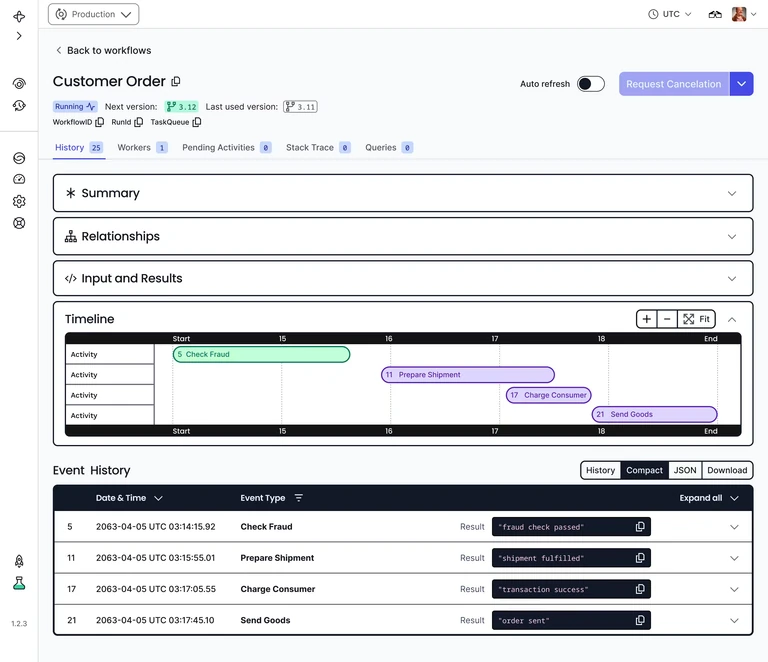
Patching an environment
1. Processing changes
When you deploy a staged change on Railway, the dashboard’s frontend sends a request to commit it as a patch. Patches applied to an environment can modify services, volumes, and variables. In the case of volumes, several types of changes may occur, including:
- Resizing
- Mounting / unmounting
- Configuring usage alerts
- Deleting a volume
On the server, the handler first performs authorization and safety checks. After loading the currently staged patch for the target environment and fetching the environment’s current configuration, it verifies:
- The user is allowed to access the environment
- If the change is destructive, the user must be an admin and complete 2FA (if configured) before proceeding
If those checks pass, the handler invokes a commitPatch backend controller to finalize the operation. Here’s what it looks like
export const commitPatch = async (
ctx: RailwayContext,
{
patch,
skipDeploys,
commitMessage,
appliedByUser,
}: {
patch: EnvironmentPatch & {
environment: Environment;
project: Project;
};
skipDeploys?: boolean | null;
commitMessage?: string;
appliedByUser?: User | null;
},
) => {
const temporalClient = await getTemporalClient();
// Start a workflow with a signal (commit patch to environment workflow)
const handle = await temporalClient.signalWithStart(
commitPatchToEnvironment,
{
signal: stagedChangesSignal, // Signal to apply staged changes
args: [
{
environment: patch.environment,
patchId: patch.id,
user: appliedByUser ?? ctx.user,
commitMessage,
skipAllDeploys: skipDeploys ?? false,
},
],
taskQueue: TASK_QUEUES.backboardEnvironments,
workflowId: commitPatchToEnvironmentWorkflowId({
environmentId: patch.environment.id,
patchId: patch.id,
}),
workflowExecutionTimeout: "2h",
searchAttributes: customSearchAttributes({
projectIds: patch.projectId,
userIds: appliedByUser?.id ?? ctx.user?.id,
}),
},
);
// Trigger event firing for this patch
await fireEventsForPatch(ctx, { patch });
// Return workflow info (useful for tracking workflow state externally)
return { workflowId: handle.workflowId, handle };
};This controller starts a new commitPatchToEnvironment workflow and sends an initial signal to it.
2. Committing a patch to an environment workflow
The commitPatchToEnvironment workflow includes several Temporal Activities, one of which is responsible for triggering a delayed volume deletion workflow
export const triggerDeleteVolumeInstances = async (ctx, { volumeId, environmentId, user, patchId, tombstone, delayDeletion }) => {
// Immediate deletion if delay not requested or info missing
if (!delayDeletion || !user || !patchId) {
return await executeDeleteVolumeInstances({ volumeId, environmentId, tombstone });
}
// Lookup active volume instance
const volumeInstance = await ctx.db.volumeInstance.findFirst({
where: { volumeId, environmentId, deletedAt: null },
});
if (!volumeInstance) throw new NotFoundError("VolumeInstance");
// Start delayed deletion workflow
const temporal = await getTemporalClient();
const workflowId = delayedDeleteVolumeInstanceWorkflowId(volumeInstance.id);
await temporal.signalWithStart(delayedDeleteVolumeInstanceWorkflow, {
signal: delayedDeleteVolumeInstanceSignal,
signalArgs: [{ action: "DELAYED_DELETION", userId: user.id }],
workflowId,
args: [{ volumeInstanceId: volumeInstance.id, tombstone, patchId, initialUserId: user.id }],
taskQueue: TASK_QUEUES.backboardEnvironments,
});
return workflowId;
};The triggerDeleteVolumeInstances function deletes a volume instance either immediately or in a delayed manner depending on the input arguments:
- If the
delayDeletionflag is false (or if required fields likeuserorpatchIdare missing), it performs an immediate deletion - Otherwise, it fetches the target volume instance from the database and uses Temporal to start or signal the
delayedDeleteVolumeInstanceWorkflow(via a unique workflow ID) that schedules the deletion for later, recording the initiating user and patch information—this allows the system to support both direct cleanup and orchestrated, trackable delayed deletions.
Scheduling volume deletion
Here’s a high-level overview of what the delayedDeleteVolumeInstanceWorkflow workflow does
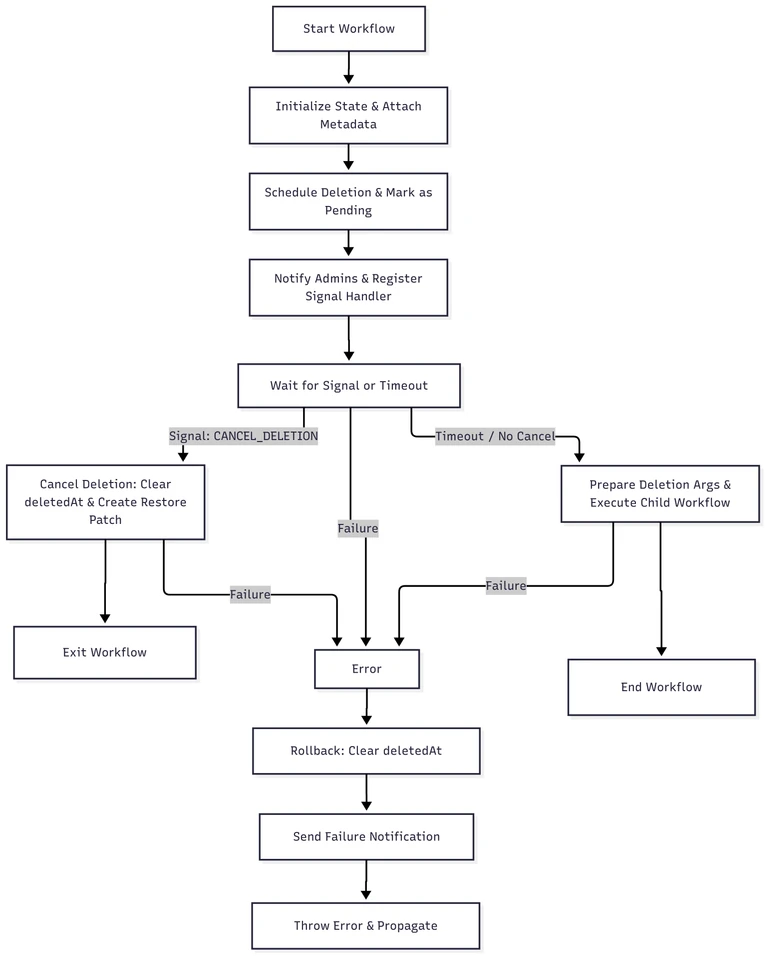
This is a simplified example of what the delayedDeleteVolumeInstanceWorkflow looks like
// simplified example
export async function delayedDeleteVolumeInstanceWorkflow({
volumeInstanceId,
tombstone,
patchId,
initialUserId,
}: {
volumeInstanceId: string
tombstone?: boolean
patchId: string
initialUserId: string
}) {
// Default to delayed deletion
let action = "DELAYED_DELETION";
let userId = initialUserId;
// Make volume searchable by attributes
await upsertVolumeSearchAttributes({ volumeId: volumeInstanceId, userId });
// Compute when deletion should occur
const deleteAt = new Date(Date.now() + VOLUME_DELETE_DELAY_MS);
try {
// Mark the volume instance with scheduled deletedAt timestamp
const volumeInstance = await updateDeletedAt({ volumeInstanceId, deletedAt: deleteAt });
// Notify admins about the scheduled deletion
await notifyScheduledDeletion({ volumeInstanceId, patchId });
// Allow external signals to cancel or override the deletion
wf.setHandler(delayedDeleteVolumeInstanceSignal, (s) => {
action = s.action;
userId = s.userId;
});
// Wait until cancellation/override OR until the grace delay expires
await wf.condition(() => action !== "DELAYED_DELETION", VOLUME_DELETE_DELAY_MS);
// If deletion is canceled: restore the volume and exit early
if (action === "CANCEL_DELETION") {
await updateDeletedAt({ volumeInstanceId, deletedAt: null });
await restoreVolumeInstance({ volumeId: vi.volumeId, environmentId: vi.environmentId, userId });
return;
}
// Otherwise, proceed with permanent deletion via child workflow
await wf.executeChild(deleteVolumeInstances, {
args: [{ volumeId: vi.volumeId, environmentId: vi.environmentId, tombstone }],
workflowExecutionTimeout: "1h", // safeguard timeout
});
} catch (err) {
// On failure: reset state and report error
await wf.CancellationScope.nonCancellable(async () => {
await updateDeletedAt({ volumeInstanceId, deletedAt: null });
await reportFailure({ volumeInstanceId, error: err, ...wf.workflowInfo() });
});
throw err;
}
}- Initialize State – Default the action to
DELAYED_DELETION, and record theinitialUserIdfor attribution. - Attach Metadata – Record searchable workflow attributes (
volumeId,userId) so the deletion can be tracked and queried later. - Schedule Deletion – Calculate a future timestamp (
deleteAt) when the volume will be eligible for deletion. - Mark for Deletion – Update the database record with the
deletedAtvalue, signaling that the volume is pending deletion. - Notify Admins – Send an email alert so administrators are aware of the scheduled deletion and can intervene if needed.
- Register Signal Handler – Listen for external signals that may cancel or override the deletion request.
- Wait for Condition or Timeout – Pause until either a cancellation signal arrives or the delay window expires.
- Handle Cancellation – If deletion is canceled, clear the
deletedAtfield, create a restore patch, and exit the workflow. - Proceed with Deletion – If no cancellation occurs, launch a child workflow to perform the permanent deletion under a strict timeout.
- Error Handling – On failure, reset the deletion state, send a failure notification with workflow details, and propagate the error.
What happens at the infrastructure level
Once the 48-hour grace period expires, the system moves from orchestration to the actual teardown of infrastructure. This process happens in two main phases: Infrastructure Cleanup and Final Cleanup.
Both are driven by Temporal workflows that coordinate database state, routers, and compute hosts, ensuring that deletions are safe, observable, and consistent across all layers of the system.
1. Infrastructure Cleanup
When the grace window ends, the delayedDeleteVolumeInstanceWorkflow spawns a child workflow that performs the actual deletion of the volume. We construct the arguments for the teardown and run the workflow with a strict timeout:
// Simplified logic
await wf.executeChild(deleteVolumeInstances, {
args: [{ volumeId, environmentId, tombstone }],
workflowExecutionTimeout: "1h",
});The child workflow iterates over all matching volume instances, deleting them one by one. This isolates errors, allows retries per instance, and provides granular observability:
// simplified logic
export async function deleteVolumeInstances({ volumeId, environmentId, tombstone }) {
for (const volumeInstance of volumeInstances) {
await volumeActivities().deleteVolumeInstance({ volumeInstanceId: volumeInstance.id, tombstone });
}
}Each instance follows the same lifecycle: mark state, detach services, remove from infrastructure, and finally clean up in the database.
export const deleteVolumeInstanceById = async (ctx, { volumeInstanceId, tombstone }) => {
// Mark schedules and state
// Detach deployments
// Remove from infrastructure
// Cleanup in database
};The router resolves the appropriate compute host node, instructs it to delete, and then tidies its own caches:
func (c *Controller) RemoveVolumeInstance(ctx context.Context, req *Request) (*Response, error) {
// Resolve compute host
// Request deletion
// Update store
return &Response{}, nil
}Finally, the compute host performs the physical destruction using ZFS with a recursive destroy:
func (g *Gateway) RemoveVolumeInstance(ctx context.Context, volumeID string) error {
// Run zfs destroy -r
// Update counters and orchestrator
return nil
}2. Final Cleanup
Once the infrastructure reports success, the system cleans up logical state in the database.
For volume instances, we either tombstone (soft-delete) with a timestamp and unique mount path, or hard-delete:
export const deleteVolumeInstanceInDatabase = async (ctx, { volumeInstanceId, tombstone }) => {
if (tombstone) {
// Mark deleted with timestamp and state
} else {
// Hard delete
}
};The parent volume record is also cleaned up with the same tombstone or hard-delete semantics:
export const deleteVolumeById = async (ctx, { volumeId, tombstone }) => {
if (tombstone) {
// Mark deleted with timestamp and name change
} else {
// Hard delete
}
};Any backup schedules or deployments tied to the volume are finalized, and finally, orchestrator updates ensure all distributed systems converge on the same state.
By the end of this process, the volume has been torn down across every layer: backups stopped, deployments detached, bytes destroyed on disk, and records reconciled in the database. This guarantees that once the grace period passes, deletion is thorough, consistent, and leaves no dangling resources behind.
Conclusion
By giving volumes a grace period before they disappear forever, we’re making infrastructure a little more forgiving, and a lot less stressful. Mistakes can always happen, but our goal is to make sure they don’t turn into disasters. Whether it’s a late-night deploy, a misclick, or simply a change of heart, you now have the safety net to undo it.
If solving hard problems, shaping resilient infrastructure, and making life easier for developers sounds like your kind of fun, we’re hiring.