Going multi-cloud with an in-housed status page
Hi, I'm Noah. I built the Railway status page. Yeah, I know what you're thinking. It gets better. The whole thing runs on Railway. You might be wondering how we got into this situation.
The challenge
Railway is not in the business of lying to people. We want folks to know whenever there is a problem immediately when there is one.
But when customers have an issue and they would visit the status page…
- It was hard for people to understand when they had an issue over the platform
- They didn’t understand the litany of components
- They felt that Railway would call incidents too late
But when customers see a service, Support and our Platform teams see:
- The host
- The network
- The storage
- I/O pressure
- Fleet availability
- 3rd party dependencies
- Builds
I can go further.
All existing solutions were simply unable to express the complexity of our infrastructure and how different components tie into different features of the product. Every product out there was either too opinionated about comms tooling, too restrictive with incident management, or were too strict with API limits that prevent us from building custom workflows on top of them.
The last note I will add is that status pages are usually binary.
Either it's an incident or it's not. The problem is the moment between "something looks weird" and "we know what this is." Usually at this time, the on-call is staring at a graph.
So we needed to add a status called a Notice. When on support rotation, customers value a message that is akin to: "we see it, we're looking." This is helpful for 99 percent of our incidents that are transient such as: builds taking longer than usual.
Our hope here is that we can be more transparent about our processes. We’re more than happy to offer an easy public acknowledgement that goes a long way without the cost of a false alarm.
Why host the status page on Railway
At Railway, we truly, truly, believe that everything that we use at Railway needs to use Railway. If we can’t trust our own product to do this, we shouldn’t be selling it to people.
The concern that comes to mind for most is “What if Railway itself goes down?”.
Railway status shouldn’t only depend on Railway. That page being broken makes a bad situation far far worse. The status page is the one surface customers will refuse to forgive you for.
So the constraints were:
- The customer-facing read path has to stay up even if the API is unreachable.
- Someone paged at 3am should be able to publish an update in under five minutes.
- Every mutation must be available via API. Admin dashboard and anything else that uses it must be a client.
So the call was: host it on Railway, and build an escape hatch for the genuinely extreme case. (Spoiler alert: we would need it.) I spec-ed the the multi-cloud escape hatch while I worked on the page itself.
Getting to the thing that's always up
While building this- the pressure was on… chaos ensued in every product and DevTool vendor out there. The customer temperature was justifiably rising Railway side. Every company was getting jokes about how they were vibecoding an outage.
I didn’t want to ship something that would embarrass the company. So I needed to do this carefully.
Railway makes it easy to deploy code from a GitHub repo, but I needed to craft the system such that if the underlying host was to be affected for any reason at all- the public page stays up.
So I put a Cloudflare Worker in front of the status page that acts as a transparent proxy.
Every request passes straight through to origin, and 99.99% of the time it does nothing interesting at all. Instead of leaning on standard cache control, the Worker runs its own stale-while-revalidate layer on top: it stamps each cached response with an x-cached-at header, serves it instantly, and if the entry is older than 5 seconds it kicks off a background refresh while you already have your page. If the origin disappears entirely, the worker serves the last good render for up to a week from whichever of Cloudflare's 300+ POPs are closest to you.
However, serving stale uptime isn’t good enough.
For a real incident we reach for the second layer: changing a single flag in Cloudflare KV.
Flip it, and the Worker stops proxying and starts rendering a curated incident page straight from KV that the support oncall can update in real time. The page itself is one self-contained HTML string, with JS bundle and no API calls there is nothing left that can fail.
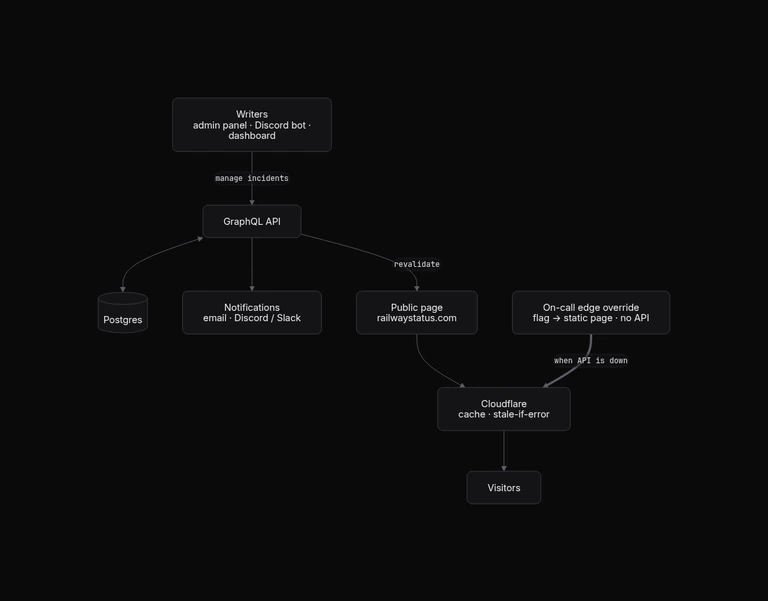
The fallback only intercepts requests that actually want HTML so JSON pollers still get JSON, and if origin throws with nothing cached we render a neutral status page instead of leaking a raw 502. The status page survives the exact outage it exists to report allowing support on-call to happily send out updates as needed.
Everyone is a cockroach now
It’s no secret that we had a bad upstream outage. But we did get questions like:
“How did Railway’s status page stay up during that outage???”
Then a follow-up…
“Why didn’t I stay up during the outage?”
To which my reply is- we weren’t fast enough to roll-out the failover mechanism to all of our customers.
That said, the first version of our technology is now live for all customers on the platform. Network engineer Mig tells me that we now have our network plane in 4 regions across both hemispheres. You’d need 4 simultaneous meteors to strike the locations of the sites to fully knock your workload down (network wise) assuming you are fully replicated.
Railway has hosts on all major clouds (namely, AWS/GCP/Railway Metal) and we have dark fiber running through all of our sites. Now when there is a underlying route failure (that got us the last outage) your workload stays up since the routing system is distributed much like the architecture that we have for the status page. …and we have a greater amount of fallbacks to make us fully disaster proof, much like what we now call: Railway Status.
What's next
Well, a logged-in view where a Railway user sees only the components that affect their services is in the cards, we’re looking into how we can directly communicate to smaller subsets of customers.
We don’t plan to sell Railway Status for now, but the backing system to make it multi-cloud for disaster scenarios is live for our customers, and we plan to extend our DR footprint for our customers in the coming months.
The public page is live at status.railway.com and going strong, I hope more than anything that you never have to see it.
If you want to work at a company where you can work on projects like building your own status page, we’re hiring across the board! https://railway.com/careers