Supercharging Directus on Railway with a Static Frontend
This is how I made the website for the Bulldog Bulletin newspaper. If you want to see the code for that, you can find it here.
This post assumes some basic knowledge of Python and Git; knowledge of GraphQL would also be useful.
Introduction
About 10 months ago, I volunteered to make a website for a newspaper. I wanted to make it usable for people who do not know, or want to know, how to push Markdown files to a Git repository. Thus, I needed a CMS - and Directus seemed like the tool for the job. There was just one slight problem, though: pulling the posts from its GraphQL API on every page load was remarkably slow, and put more load than it seemed was necessary on the Directus server.
So, I did the obvious thing, and decided to roll my own static site generator in Python. Here's how you can, too.
Setting Up Directus
One of the easiest ways to get started with Directus is on Railway - just deploy this template, head to the deployed site (log in with the ADMIN_EMAIL that you set when deploying and the ADMIN_PASSWORD from the service's Variables tab) and you should be set. Then, make a collection for your content - for this tutorial, we'll call it articles. This is what my data structure looks like, but you can make a simpler one - say, id, status, author, published_at, title, summary, and content:
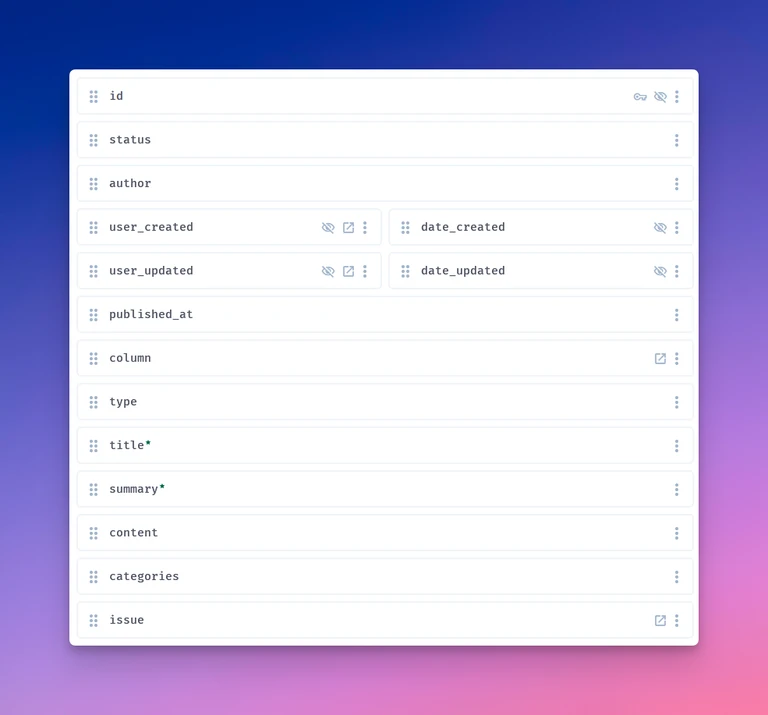
That's the only collection you really need for this tutorial - the Bulletin also has columns and issues, but those shouldn't be necessary for a simple blog.
Writing The Code
Note: this guide won't cover specific template layouts, styling, etc. - if you want to get inspiration on those, feel free to follow the GitHub link at the top of this post.
Directus has some great SSG and framework integrations - Astro, Nuxt, and 11ty, for instance, are all great options. When I tried to use Nuxt for this project, though, I started off with an SSR site. This had the advantage of being always up to date (something that we'll get to for the static site in a bit), but was slow, and file-based routing felt inflexible. Nuxt as a SSG fixes the first problem, but the second is still there.
So, I decided to build my own, in Python.
Setting Up A Project
I decided to use Pixi to manage this project. Really, any Python project manager would work - were I starting it today, I might use Poetry for better IDE support - but Pixi is extremely fast and has a flexible enough task runner for my purposes. Again, if you want to see the build scripts, you can take a look here; this guide will focus on the Python code.First of all, it's dangerous to go alone; take these dependencies:
gql-with-aiohttpfor connecting to the Directus GraphQL APIjinja2for templatingslugifyfor turning post titles into slugs (alternatively, you could set up a custom slug field in the database, but I'll leave that as an exercise for the reader)dateutilfor formatting published dates- ... and your preferred styling library, etc. I used
dart-sassfor the Bulldog Bulletin.
If you're using Pixi, you can set up the project with:
$ pixi init
$ pixi add python gql-with-aiohttp jinja2 dart-sass python-slugify python-dateutilNow that you have a project, let's put some code in it!
Connecting to Directus
We're going to use the Directus GraphQL API for this, as it allows us to get all of our data in one fell swoop:
query {
articles(filter: {
status: {
_eq: "published"
}
}, sort: ["-published_at"]) {
id
author
date_created
date_updated
published_at
type
title
categories
summary
content
issue { id }
column {
name
id
description
}
}
issues(filter: {
status: {
_eq: "published"
}
}, sort: ["-published_at"]) {
id
published_at
}
}Neat, eh? This query is for the Bulldog Bulletin, so it has some parts - like fetching relations for issue and column - that might not apply to your data. What it does, in a nutshell, is take all of the data we need from all published articles and issues, sorted descending by publish date.
Here's the Python code that wraps it - put this in utils/directus.py in your project:
from gql import gql, Client
from gql.transport.aiohttp import AIOHTTPTransport
transport = AIOHTTPTransport('https://bulletin-cms.burrburton.org/graphql')
client = Client(transport=transport, fetch_schema_from_transport=True)
def exec(query: str):
return client.execute(gql(query))
def everything():
return exec("""
your query here
""")Compiling Templates
So far, our static site generator isn't much of a static site generator. Let's compile some templates. Put this in utils/gen.py:
from datetime import datetime
from dateutil import parser
from pathlib import Path
from jinja2 import Environment, FileSystemLoader, select_autoescape
from slugify import slugify
sitemap_baseurl = 'https://bulldog.burrburton.org'
sitemap_urls: list[str] = []
env = Environment(
loader=FileSystemLoader("templates"),
autoescape=select_autoescape(
enabled_extensions=("html", "xml", "j2")
),
)
def fmt_date(date_str: str, date_only: bool = False) -> str:
format_str = "%m/%d/%Y" if date_only else "%b %d, %Y, %I:%M %p E.T."
return parser.parse(date_str).strftime(format_str)
env.globals.update(
slugify=slugify,
fmt_date=fmt_date
)
def compile_template(name: str, out_path: str, *args, **kwargs):
print(f'compile: {out_path}')
template = env.get_template(name + ".j2")
out_dir = f'public{out_path}'
out_file = f'{out_dir}index.html' if out_path == '/' else (
f'{out_dir}' if out_path == '/sitemap.xml' else
f'{out_dir}/index.html')
Path(out_dir).mkdir(parents=True, exist_ok=True) if out_path != '/sitemap.xml' else None
with open(out_file, 'w') as f:
f.write(template.render(*args, **kwargs))
sitemap_urls.append(sitemap_baseurl + out_path)
def write_sitemap():
compile_template('sitemap.xml', '/sitemap.xml', urls=sitemap_urls)Let's break that down. First of all, it loads all of the templates from the templates directory of your project, and provides the slugify method as well as a custom date formatting method to the template. (This code formats dates for Eastern Time; if you don't live in Eastern Time, you might want to change that.) Then, it provides a compile_template method, which will, given the path at which you expect the page to show up on the website, put an HTML file at index.html under that path. The last method, compile_sitemap, compile's the website's sitemap for better SEO - we'll come back to that one in a couple of paragraphs.
Putting (Most Of) It All Together
Put this in build.py at the root of the project; if you're just using articles, without categories or issues, you can remove everything between line 16 and line 41:
from slugify import slugify
from utils import directus
from utils.gen import compile_template, write_sitemap
data = directus.everything()
compile_template('index', '/', data)
tags_compiled = set()
for article in data['articles']:
compile_template(
'article',
f'/articles/{article['id']}',
data, article=article
)
for tag in article['categories']:
if tag not in tags_compiled:
tags_compiled.add(tag)
compile_template('category', f'/c/{slugify(tag)}', data,
tag=tag,
filtered_articles=[
article for article in data['articles']
if tag in article['categories']
]
)
for issue in data['issues']:
issue_articles = [
article for article in data['articles']
if
article['issue'] is not None
and article['issue']['id'] == issue['id']
]
compile_template(
'issue',
f'/issues/{issue['id']}',
data, issue=issue, issue_articles=issue_articles
)
write_sitemap()This should be relatively easy to understand: first, it gets all of the data from Directus; then, it compiles the homepage; then, it compiles the articles, ensuring for each article that all of its tags have pages too; and finally, it builds a page for each issue. After it's written all of the pages, it writes the sitemap (remember that compile_template keeps track of all of the pages that have been compiled so far, and write_sitemap uses that list).
You may, at this point, notice that something's still missing. We keep compiling templates, but we don't have any templates to compile yet.
The Actual UI
I'll leave this part mostly as an exercise to the reader; all of the templates I used are available in the templates folder of the GitHub repository, but you probably have plans for your particular site that are very different from those I had for the Bulldog Bulletin. I will, however, give a couple of pointers. Firstly, a basic sitemap (in sitemap.xml.j2) is as simple as:
<?xml version="1.0" encoding="utf-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
{% for url in urls %}
<url>
<loc>{{ url }}</loc>
</url>
{% endfor %}
</urlset>Another feature the Bulldog Bulletin has is short-form post support, where a truncated version of a post is shown on the homepage and HTMX is used to expand it if the user clicks "Read More". That can be implemented like so (where article is a loop variable, iterating over each article):
<div class="post-preview">
<!-- Author, published date, etc. go here -->
<div class="post-content" id="post-content-{{ article.id }}">
{% set truncated = article.content | truncate %}
<p>{{ truncated | safe }}</p>
{% if truncated != article.content %}
<button class="swap-content" hx-get="/articles/{{ article.id }}" hx-select="article"
hx-target="#post-content-{{ article.id }}" hx-swap="outerHTML" hx-preserve="title">
Read More
</button>
{% endif %}
</div>
</div>These articles still have pages built for them, but this code uses HTMX to select only the element from that page (which is assumed to contain the article content) and display it when the user clicks "Read More".
Deployment
This is just a static site, so I use GitHub Actions to deploy it. The workflow is relatively simple (assuming Pixi) - save it in .github/workflows/static.yml:
name: Deploy site
on:
push:
branches: ["main"]
workflow_dispatch:
repository_dispatch: # THIS IS IMPORTANT! This allows you to trigger deployments from Directus flows, which we'll get to in a bit.
permissions:
contents: read
pages: write
id-token: write
concurrency:
group: "pages"
cancel-in-progress: false
jobs:
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- uses: prefix-dev/setup-pixi@v0.2.0
- name: Build
run: pixi run build
- name: Setup Pages
uses: actions/configure-pages@v3
- name: Upload artifact
uses: actions/upload-pages-artifact@v2
with:
path: 'public'
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v2This will automatically deploy whenever we change the code. To rebuild when we change the content, though, we need to set up a Directus flow. Make one called "GitHub Pages Rebuild", or something descriptive. Here's the basic layout:
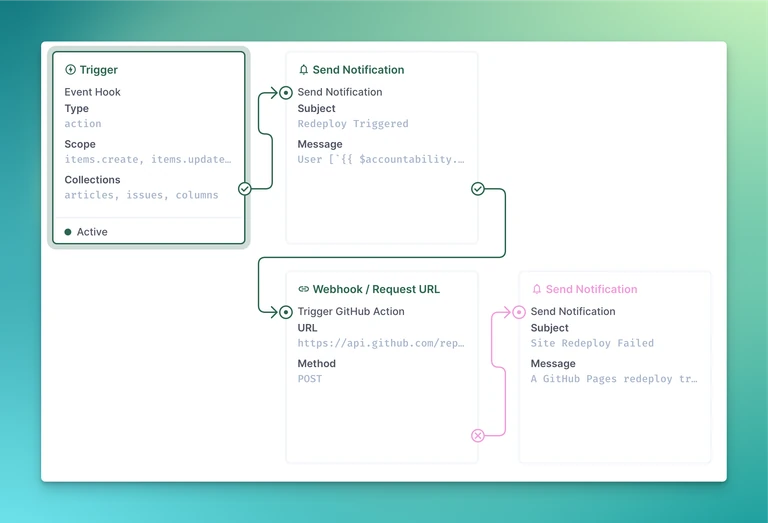
For the trigger, select all of the collections that have content that you want to watch for changes. The first notification should be sent to whoever is in charge of the Directus instance (i.e. you), and have content along the lines of:
User [`{{ $accountability.user }}`](/admin/users/{{ $accountability.user }}) has triggered a site redeploy.The webhook is where it gets interesting. This will request an Actions run. The URL should look something like *https://api.github.com/repos/you/your.site/actions/workflows/static.yml/dispatches*. Then, if you want to be notified if that request errors, you can add the failure notification, which can have whatever text you want.
That should be it! If you have any questions, you can reach out to me on Mastodon or the Railway Discord or Forum (@aleks, the conductor, on both).