Scaling a SaaS application on Railway
In the previous tutorial, you built a job board SaaS application using Remix, PostgreSQL, and Railway. You also deployed it to the internet with a custom domain and Cloudflare proxy. In this article, you’ll learn to scale the SaaS to handle high traffic, improve performance, and tackle some of the challenges that come with design choices. You’ll also learn about various techniques to save cost of running your SaaS application, while keeping the user experience on par.
Continuous deployment
Continuous deployment is an automated process in which code changes are tested, verified, and automatically pushed to the live environment. This ensures that updates or new features are continuously delivered to users without manual intervention, speeding up the development cycle.
Railway automatically deploys the latest commits to the main branch of the connected GitHub repository. But as your application grows and you ship more features, you need to ensure that the features are tested on a live environment before serving the customers to ensure they work properly outside your development machine.
To solve this problem, you can use the Railway environments feature to create an isolated environment called Staging for your project that you can manage without affecting services in the production environment. You can link the Staging environment to the stage branch. All the new features are first merged into the stage branch and tested on the staging environment before serving the customer, as shown in the following diagram.
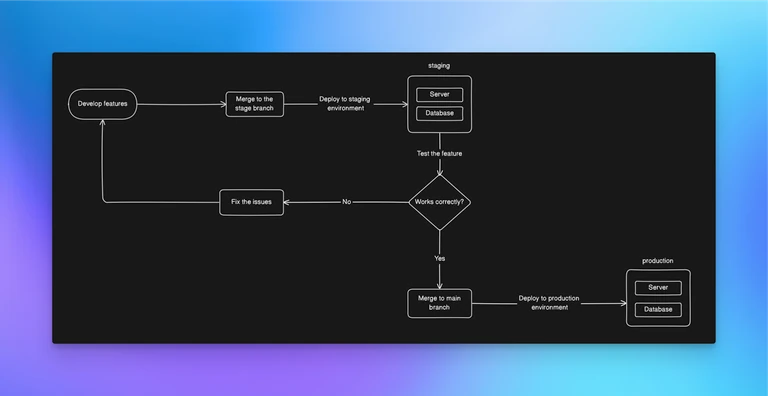
To implement this solution, follow these steps:
- In your Git project, create a new branch named
stagefrom themainbranch. - Push the
stagebranch to GitHub. - In your Railway dashboard, go to your project page.
- Click production > New Environment: New Environment dialog opens.
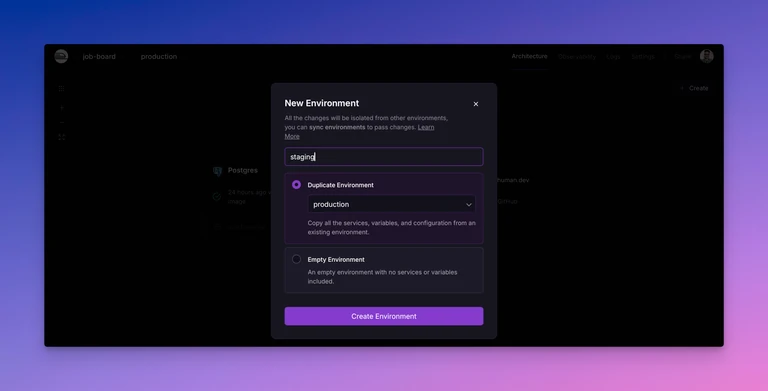
- In the Name field, enter staging.
- Select Duplicate Environment.
- Click Create Environment.
- Click Deploy.
This creates a new staging environment and sets up the same services as the production environment.
You’ll notice that Railway has automatically imported the environment variables from the production environment and replaced the DATABASE_URL with the database URL of the PostgreSQL instance of the staging environment. Railway has also assigned a public domain name to this environment and similar to the production environment you can also add a custom domain to it.
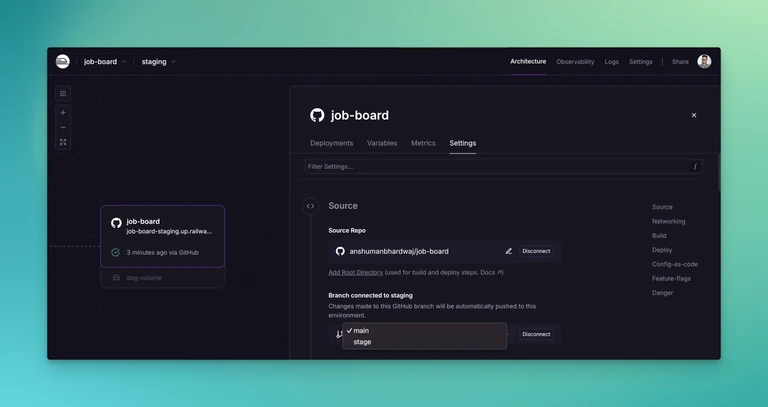
Now in the staging environment
- Go to job-board > Settings > Source > Branch connected to staging and select
stagebranch.
Railway will automatically deploy your application for every new commit on the connected branch and you don’t have to worry about it because Railway performs zero downtime deployments, which means that the previous version of the application is kept running until the new version passes the health checks. If something goes wrong in a new deployment, you can also perform a one-click rollback to any previously deployed version of the application from the Deployments section.
Handle high traffic
For any new SaaS product, it’s hard to calculate how many resources are required to serve the customers because the traffic patterns are unpredictable. The easiest solution to tackle this is to over-allocate resources, while it is rarely the best decision when you’re not making money off the product.
There are two ways to scale your application deployment:
- Vertically: by adding more resources to a single machine.
- Horizontally: by adding more machines that handle requests independently.
Railway supports both approaches and even mixes them up quite well for the best experience.
Vertical scaling
Railway auto-scales your application resources based on traffic and consumption. This is helpful for both upscaling to handle as many requests as you want and to downscaling when there is not many users for the application. This is all done automatically and you can check the resource usage metrics from job-board > Metrics tab to see the historical usage patterns for up to 30 days.
Horizontal scaling
With Railway you can add replicas to your service and distribute the incoming request load between multiple instances. Replicas are also auto-scaled vertically giving it the best of both worlds. Because the job board application does file upload processing which is a long-running task it is a good idea to have multiple instances of the application running.
To add the replica to the production environment -
- Go to job-board > Settings > Replicas.
Here you can increase the count to any number based on your requirement.
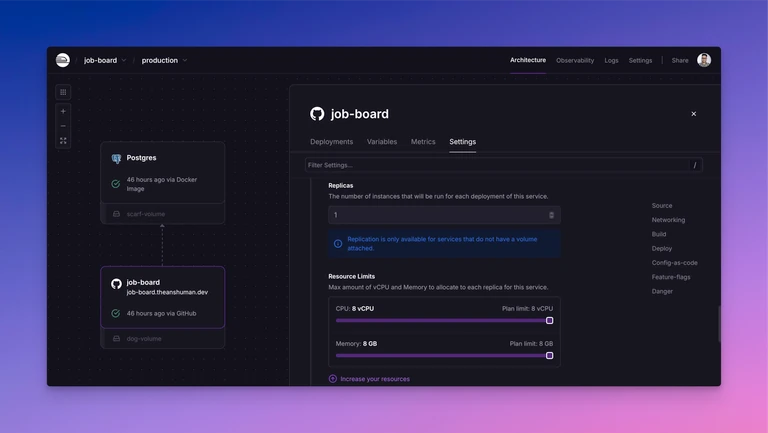
You’ll notice that Railway doesn’t let you add replicas just yet because the job-board service is using a persistent volume. To tackle this issue, you need to decouple the storage from the job-board service by adding an external storage to your service.
Global distribution
To improve application performance and user experience of your application, you can also choose a deployment region closer to your primary customers. With Railway you can do so from the job-board > Settings > Region settings.
You can also use global CDN networks such as Cloudflare or AWS Cloudfront to serve static content faster. More on this in the next section.
Cost management
When starting a SaaS business, it’s important to regularly gauge the cost of running the application so that you can optimize the code or architecture choices to better use the resources available and keep the cost to a minimum. Railway provides many features out-of-the-box to reduce cost of running your application.
Cache static content on using Cloudflare
It’s a good practice to cache the static content or public content that changes seldom on the CDN level. By doing so, you reduce the number of requests to your origin server (Railway) and in turn, reduce the resource consumption and load.
The job details page in this project is a good example of such optimization. Because the job details are supposed to be changed seldom and this gives you the opportunity to leverage HTTP caching.
Remix lets your return route level headers that you can use to add the Cache-Control HTTP header for client-side and CDN level caching.
- Add the following code snippet to the
app/routes/jobs.$jobId.tsxfile. This will cache the job details pages for 3600 seconds or 1 hour.
export const headers: HeadersFunction = () => {
return {
"Cache-Control": "public, max-age=3600, s-maxage=3600", // cache for 1 hour
};
};Because you’ve not implemented cache purge on-page content changes, it’s important to inform your customers about the caching behavior to avoid confusion when they edit the page.
After the application is deployed, visit the page to confirm if the caching is applied using the browser dev tools.
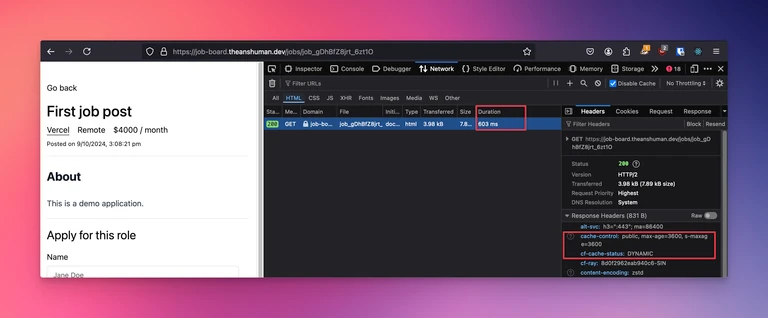
You’ll notice that the response time is still quite high due to latency between the us-west region and India. You’ll also see that even though the cache-control header is returned in the response, Cloudflare didn’t utilize it. This is because you need to set up caching rules on the CDN level to activate the cache control header usage. This project is using Cloudflare proxy network but the same steps will apply to other CDNs as well.
To set up the cache rule in Cloudflare, follow these steps:
- Open your Cloudflare dashboard, go to Site > Caching > Cache rules.
- Click Create rule.
- In the Name field, enter
cache job details pages. - In If incoming requests match… section, select Custom filter expression.
- For Field, select URI Full.
- For Operator, select wildcard.
- For Value, enter
https://YOUR_APP_DOMAIN_NAME/jobs/*because you only want this rule to apply to the job details page.
- In Cache eligibility, select Eligible for cache.
- In Edge TTL, select Use cache-control header if present, bypass cache if not. To cache the page at the CDN level.
- In Browser TTL, select Respect origin TTL. To cache the page in the user’s browser.
- Click Save.
After a few seconds, try to reload the page a few times and you’ll notice that the response is cached and response time also is much lower. You can confirm the cache hit status with the cf-cache-status response header.
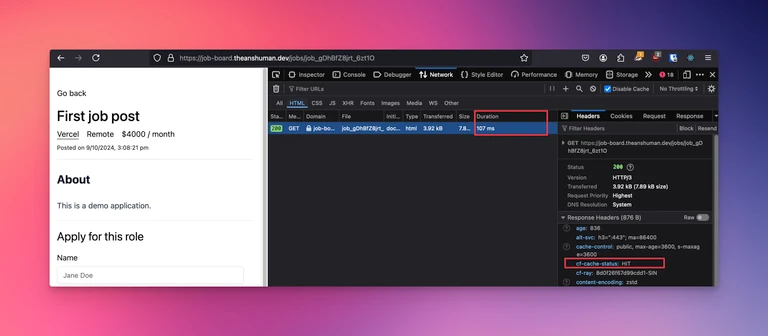
Save cost on Railway
Railway automatically handles scaling up and down for you, which means you’re never paying more than what your application is using. But there are ways in which you can reduce your costs even more. For example:
- App sleeping: Railway will stop the container after a period of no traffic on your service and when the traffic resumes, the application is restarted automatically. This is a good way to reduce the cost of your secondary environment, in this case, staging, because it is only used to test changes and not by the customers.
- Reduce egress: It’s also a good idea to use private networking between services to avoid extra egress fees. When using distributed storage services, you should use pre-signed Get object URLs instead of downloading and returning the file from the Railway app to avoid double-egress fees: once from the storage provider and then by Railway.
Add external storage for horizontal scaling
To tackle this issue, you can use a distributed storage service such as AWS S3 or Cloudflare R2, but they add up to the cost because of the egress fees. You can instead use an open-source alternative such as MinIO, which will also not incur any egress fees because you can deploy it within your Railway project. You can follow along this tutorial using this GitHub repository.
To create a MinIO instance in your Railway project, follow these steps:
- Open the project page in your Railway dashboard.
- Click Create.
- Click Template.
- Search and select MinIO.
This will add a MinIO service group with the console and bucket to your project. Click on Console and open the console URL in a new browser tab.
On the MinIO Console login page,
- In the username field, enter the value of the
USERNAMEvariable from the Console service. - In the password field, enter the value of the
PASSWORDvariable from the Console service.
This will open the MinIO console for you.
- In the left navigation menu, click Buckets and then click Create Bucket.
- Create a bucket called
job-board-prodfor the production environment and another one calledjob-board-devto use for local development.
For brevity, this tutorial uses the production environment instance of the MinIO for development but you should set it up locally as well.
- Now go to the Access Keys in the MinIO Console and click Create Access Key to create a new key.
- Copy the credentials and save them in the
.envfile of your local project as follows:
MINIO_ACCESS_KEY=<paste-the-value-here>
MINIO_SECRET_KEY=<paste-the-value-here>
MINIO_BUCKET=job-board-devIt’s recommended to apply strict access rules when creating access keys. To learn more about Policy-Based Access Control (PBAC), see Access Management.
Now go to your Railway project page
- Select MinIO Bucket service.
- From the Variables tab, copy the value of the
MINIO_PUBLIC_ENDPOINTvariable and add it to your local.envfile.
You need to use the public endpoint only to access outside of the Railway network.
MINIO_ENDPOINT=<paste-the-value-here>MinIO is S3 compatible so you can use it directly with the AWS S3 clients in your application.
- Run the following command in the local project to install the AWS S3 Typescript client
npm i @aws-sdk/client-s3 @aws-sdk/s3-request-presigner- Update the
app/routes/jobs.$jobId.tsxfile to configure the S3 client, - Upload the file to MinIO and delete the uploaded file from the server disk.
- Update the resume download code in the
app/routes/dashboard.$jobId.$applicantId.resume.tsxfile, to return a pre-signed URL of the file from MinIO instead of returning it from the local disk. - Merge the code to the
stagingbranch. - Add the MinIO service to the staging environment on Railway.
- Create a new bucket called
job-board-stage. - Add the MinIO credentials to the service environment variables.
- Create a new access key for the staging environment and update the
BUCKET_NAMEwithjob-board-stage. - Test the application on staging and merge the
stagingbranch into themainbranch. - Update the MinIO credentials on the production environment and set the
BUCKET_NAMEwithjob-board-prod.
After the deployment finishes your application can now work without persistent volumes, which means you can now add more replicas to your service and horizontally scale the SaaS application.
To remove the volume, right-click it and select Delete volume. Confirm the deletion in the next step.
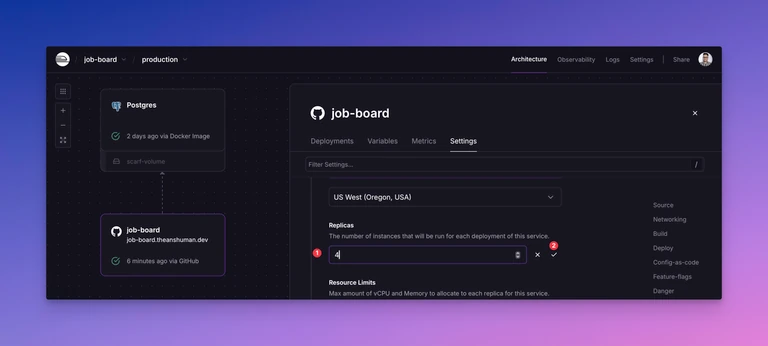
Now go to job-board > Settings > Replicas, update the replicas count to 4 and save the changes. You’ve now 4 instances of the job-board service running and Railway will automatically distribute the incoming requests to these instances.
Conclusion
After completing this tutorial, you will have learned about scaling up a SaaS application on the Railway. You also learned about utilizing object storage and HTTP caching for better performance. It is important to understand that when getting starting speed is important to validate the ideas quickly and using services such as Railway helps you as a solopreneur to ship your ideas as fast as possible.